Power tool for Messy Data
One of Refine’s strengths is the flexibility to handle all sorts of data from all sorts of sources.
Import formats: CSV, TSV, custom separator, Excel, ODS spreadsheet, XML, JSON, RDF, Google Sheets, MARC, line-based text…
Import sources: local file(s), archive (zip), URL, clipboard, database, or Google Sheets.
Output formats: TSV, CSV, HTML, Excel, ODS spreadsheet, SQL, Wikidata, RDF schema, or custom template…
When creating a new project, Refine imports the data without changing the original source, saving a copy using an optimized format in the “workspace directory” on your computer. Importantly, Refine is not a cloud based service, no data is sent off your computer during this process (see where data is stored and data privacy FAQ).
Once imported into a project, Refine’s interface represents the data in a tabular grid, using this basic terminology:
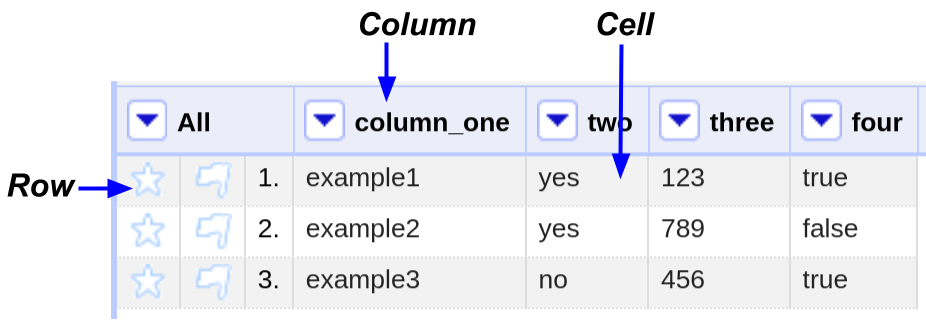
Refine is efficient enough to provide comfortable performance up to 100,000’s of rows. For very large data sets, you may want to increase memory allocation.
Messy Data
Inconsistent formats, unnecessary white space, extra characters, typos, incomplete records, etc… Messy data is the bane of analysis!
For example, each column contains exactly the same info:
| 2015-10-14 | $1,000 | ID |
| 10/14/2015 | 1000 | I.D. |
| 10/14/15 | 1,000 | US-ID |
| Oct 14, 2015 | 1000 dollars | idaho |
| Wed, Oct 14th | US$1000 | Idaho, |
| 42291 | $1k | Ihaho |
Multi-valued cells limit ability to manipulate, clean, and use the data:
| “Using OpenRefine by Ruben Verborgh and Max De Wilde, September 2013” | ||
| “University of Idaho, 875 Perimeter Drive, Moscow, ID, 83844, p. 208-885-6111, info@uidaho.edu” |
Luckily, Refine provides powerful visualizations and tools to discover, isolate, and fix these types of data issues.
Unfortunately, there isn’t a lot of literature out there about standards for wrangling and cleaning data–it has been a behind the scenes art that consumes a lot of hidden labor in a project. It is essential for the process of analysis, as well as for preparing your data for preservation and reuse. Documenting your process and being transparent will help both yourself and others understand your data set–and shed light on the important work that has gone into it.