ChronAm Example: URL API Queries and Parsing JSON
Adapted from my lesson published at Programming Historian, Fetching and Parsing Data from the Web with OpenRefine.
Many cultural institutions provide web APIs allowing users to access information about their collections via simple HTTP requests. These sources enable new queries and aggregations of text that were previously impossible, cutting across boundaries of repositories and collections to support large scale analysis of both content and metadata. This example will harvest data from the Chronicling America project to assemble a small set of newspaper front pages with full text. Following a common web scraping workflow, Refine is used to construct the query URL, fetch the information, and parse the JSON response.
Chronicling America is fully open, thus no key or account is needed to access the API and there are no limits on the use. Other aggregators are often proprietary and restricted. Please review the specific terms of use before web scraping or using the information in research.
Start “Chronicling America” Project
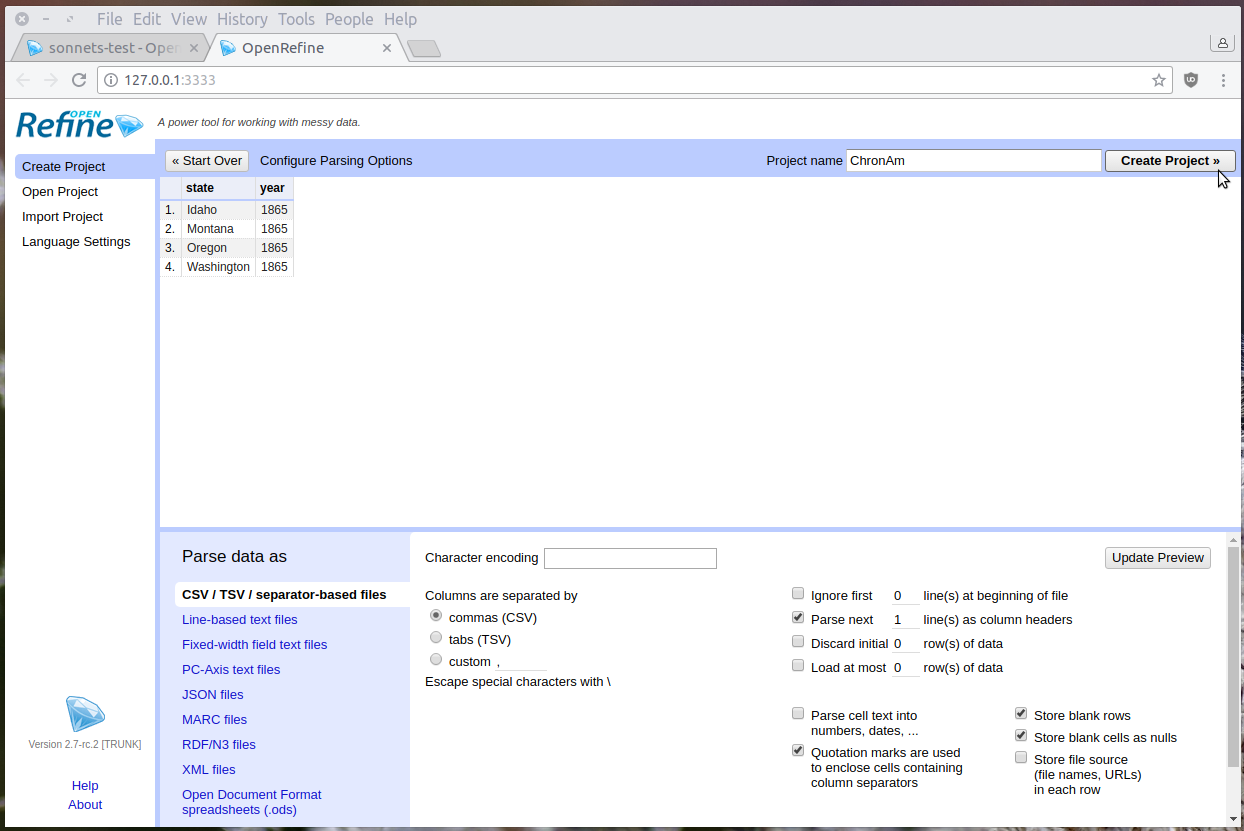
Start OpenRefine and select Create Project. Create a project from Clipboard and paste this CSV into the text box:
state,year
Idaho,1865
Montana,1865
Oregon,1865
Washington,1865
After clicking Next, Refine should automatically identify the content as a CSV with the correct parsing options. Add the Project name “ChronAm” at the top right and click Create project.
Construct a Query
Chronicling America provides documentation for their API and URL patterns.
In addition to formal documentation, information about alternative formats and search API are sometimes given in the <head> element of a web page.
Check for <link rel="alternate", <link rel="search", or <!-- comments which provide hints on how to interact with the site.
These clues provide a recipe book for interacting with the server using public links.
The basic components of the ChromAm API are:
- the base URL,
http://chroniclingamerica.loc.gov/ - the search service location for individual newspaper pages,
search/pages/results - a query string, starting with
?and made up of value pairs (fieldname=value) separated by&. Much like using the advanced search form, the value pairs of the query string set the search options.
Using a GREL expression, these components can be combined with the values in the “ChronAm” project to construct a search query URL.
The contents of the data table can be accessed using GREL variables.
As introduced in Example 1, the value of each cell in the current column is represented by value.
Values in the same row can be retrieved using the cells variable plus the column name.
There are two ways to write a cells statement: bracket notation cells['column name'].value which allows column names that include a space, or dot notation cells.column_name.value which allows only single word column names.
In GREL, strings are concatenated using the plus sign.
For example, the expression "one" + "two" would result in “onetwo”.
To create the set of search queries, from the state column, add a column named “url” with this expression:
"http://chroniclingamerica.loc.gov/search/pages/results/?state=" + value.escape('url') + "&date1=" + cells['year'].value.escape('url') + "&date2=" + cells['year'].value.escape('url') + "&dateFilterType=yearRange&sequence=1&sort=date&rows=5&format=json"
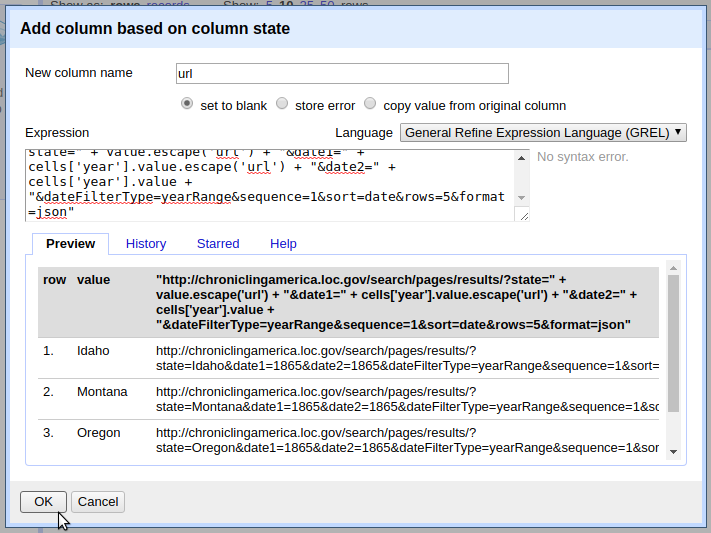
The expression concatenates the constants (base URL, search service, and query field names) together with the values in each row.
The escape() function is added to the cell variables to ensure the string will be safe in a URL (the opposite of the unescape() function introduced in Example 1).
Look at the value pairs after the ? to understand the parameters of the search.
Explicitly, the first query URL will ask for newspapers:
- from Idaho (
state=Idaho) - from the year 1865, (
date1=1865&date2=1865&dateFilterType=yearRange) - only the front pages (
sequence=1) - sorting by date (
sort=date) - returning a maximum of five (
rows=5) - in JSON (
format=json)
Fetch URLs
The url column is a list of web queries that could be accessed with a browser. To test, click one of the links. The url will open in a new tab, returning a JSON response.
Fetch the URLs using url column Edit column > Add column by fetching urls. Name the new column “fetch” and click OK. In a few seconds, the operation should complete and the fetch column will be filled with JSON data.
Parse JSON to Get Items
The first name/value pairs of the query response look like "totalItems": 52, "endIndex": 5.
This indicates that the search resulted in 52 total items, but the response contains only five (since it was limited by the rows=5 option).
The JSON key items contains an array of the individual newspapers returned by the search.
To construct a orderly data set, it is necessary to parse the JSON and split each newspaper into its own row.
GREL’s parseJson() function allows us to select a key name to retrieve the corresponding values.
Add a new column based on fetch with the name “items” and enter this expression:
value.parseJson()['items'].join("|||")
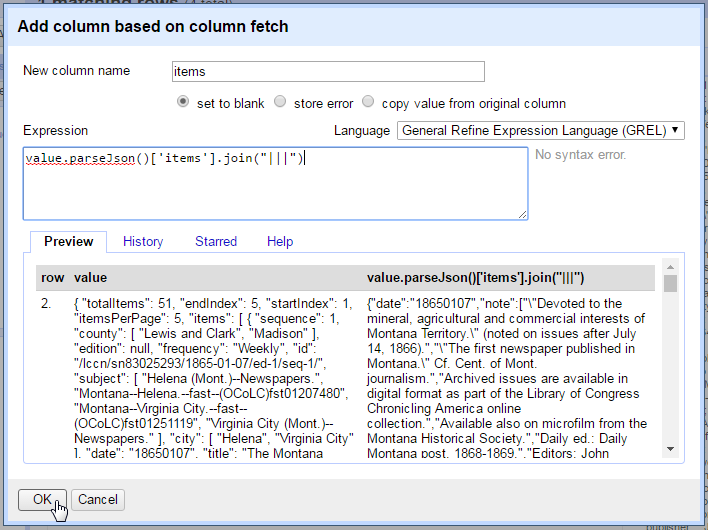
Selecting ['items'] exposes the array of newspaper records nested inside the JSON response.
The join() function concatenates the array with the given separator resulting in a string value.
Since the newspaper records contain an OCR text field, the strange separator “|||” is necessary to ensure that it is unique and can be used to split the values.
Split Multivalued Cells
With the individual newspapers isolated, separate rows can be created by splitting the cells.
On the items column, select Edit cells > Split multivalued cells, and enter the join used in the last step, |||.
After the operation, the top of the project table should read 20 rows.
Clicking on Show as records should read 4, representing the original CSV rows.
Notice that the new rows are empty in all columns except items.
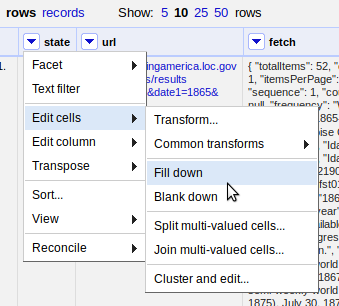
To ensure the state is available with each newspaper issue, the empty values can be filled using the Fill down function.
Click on the state column > Edit cells > Fill down.
This is a good point to clean up the unnecessary columns. Click on the All column > Edit columns > Re-order / remove columns. Drag all columns except state and items to the right side, then click OK to remove them.
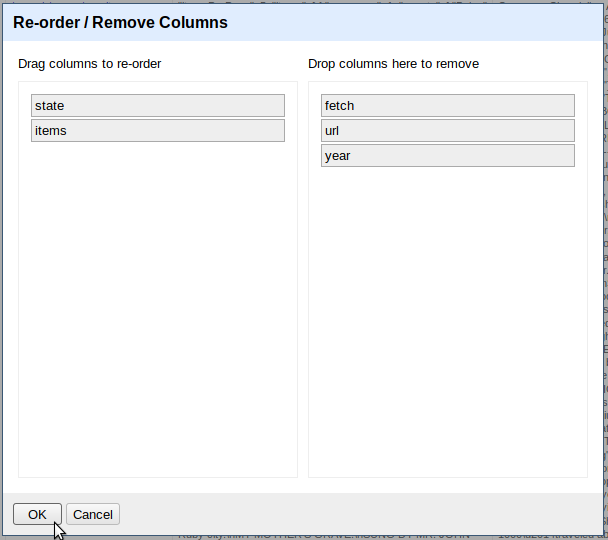
Sanity check: with the original columns removed, both records and rows will read 20. This makes sense, as the project started with four states and fetched five records for each.
Parse JSON Values
To complete the data set, it is necessary to parse each newspaper’s JSON record into individual columns.
This is a common task, as many web APIs return information in JSON format.
Again, GREL’s parseJson() function makes this easy.
Create a new column from items for each newspaper metadata element by parsing the JSON and selecting the key:
- “date”,
value.parseJson()['date'] - “title”,
value.parseJson()['title'] - “city”,
value.parseJson()['city'].join(", ") - “lccn”,
value.parseJson()['lccn'] - “text”,
value.parseJson()['ocr_eng']
After the desired information is extracted, the items column can be removed using Edit column > Remove this column.
Each column could be further refined using other GREL transformations.
For example, to convert date to a more readable format, use GREL date functions.
Transform the date column with the expression value.toDate("yyyymmdd").toString("yyyy-MM-dd").
Another common workflow is to extend the data with further URL queries.
For example, a link to full information about each issue can be formed based on the lccn.
Create a new column based on lccn using the expression "http://chroniclingamerica.loc.gov/lccn/" + value + "/" + cells['date'].value + "/ed-1.json".
Fetching this URL returns a complete list of the issue’s pages, which could in turn be harvested.
For now, the headlines of 1865 from the Northwest are ready to enjoy!